
Q: CSVファイルから読み込んだフィーチャーのある属性に、次のような書式で日付/時刻の値が格納されています。この文字列を年、月、日、時、分、秒の値に分割するにはどのような方法がありますか。
2019/11/08 12:34:56FME 2019.2
A: AttributeSplitter によって文字列を任意の区切り文字(列)の位置で分割することができます。ただし、区切り文字(列)は同一である必要があるため、このケースでは、StringReplacer などによって3種類の区切り文字(スラッシュ、スペース、コロン)を事前に同一の文字列(例えばカンマ1個)に置き換えておく必要があります。
StringReplacer
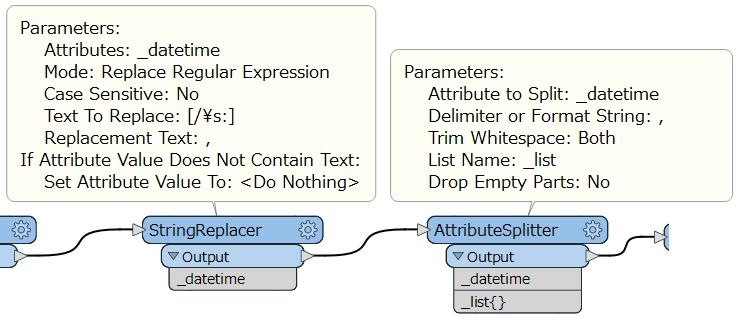
StringReplacer は、入力フィーチャーの属性のうち Attributes パラメーターで指定した属性の値について、Text to Replace パラメーターで指定した文字列または正規表現(Regular Expression)に一致する部分を Replacement Text で指定した文字列に置き換えます。置き換えるべき部分を特定の文字列、正規表現のどちらで指定するかは、Mode パラメーターで指定します(Replace Text または Replace Regular Expression)。
次のパラメーター設定例では、入力フィーチャーの”_datetime”属性の値(文字列)について、正規表現 [/\s:](スラッシュ、スペース類、またはコロン)に一致する部分をカンマ(,)に置き換えます。なお、日本語版 Windows のインターフェース上では通常、次の図のようにバックスラッシュ \ が半角の¥(円マーク)で表示されますので、適宜読み替えてください。
AttributeSplitter
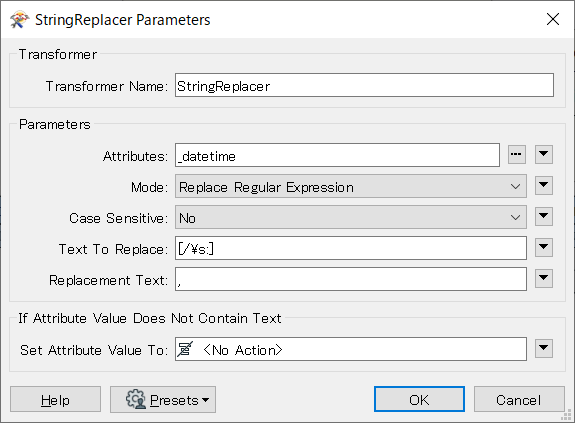
AttributeSplitter は、入力フィーチャーの属性のうち Attribute to Split パラメーターに指定した属性の値を、Delimiter or Format String パラメーターで指定した文字列で分割し、分割後の個々の部分文字列を List Name パラメーターで指定した名前のリスト属性に格納してフィーチャーに追加します。
次のパラメーター設定例では、”_datetime”属性の値(StringReplacer によって全ての区切り文字ががカンマに置換されている)をカンマで分割し、その結果を”_list”という名前のリスト属性に格納します。
リスト属性について
FMEが事物をモデル化するためのデータ構造としてのフィーチャーは、単一の値を格納する通常の属性のほかに、波カッコ { } で括られたインデクス(0から始まる連番)によって識別される任意の個数の要素で構成されるリスト属性を持つことができます。
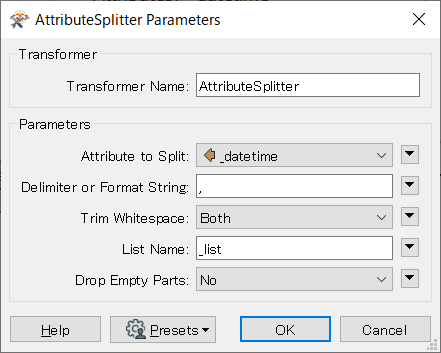
上の AttributeSplitter の例では、分割後の文字列(日付/時刻の要素)は次の要素で構成されるリスト属性に格納されます。
| _list{} リストの要素 | _list{i} の値 |
|---|---|
| _list{0} | 2019 |
| _list{1} | 11 |
| _list{2} | 08 |
| _list{3} | 12 |
| _list{4} | 34 |
| _list{5} | 56 |
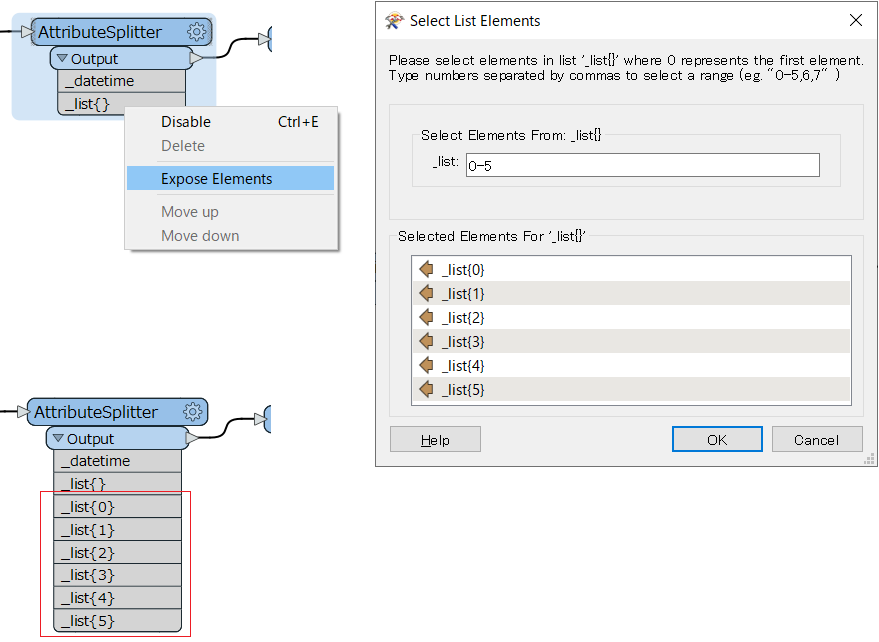
FME Workbench のインターフェースでは通常、リスト属性はリスト名と空の波カッコのペア(例: _list{})で表示されますが、個別の要素(_list{0}, _list{1} など)を使った処理を行いたいときは、それらをインターフェース上に現す必要があります。
ひとつの方法は、トランスフォーマーのインターフェースに表示されているリスト属性名(例: _list{})を右クリック > Expose Elements を選択して Select List Elements(リスト要素の選択)画面を開き、現したい要素のインデクスを指定することです。その場合、下の図のように現したい要素の範囲をハイフン区切りで指定するほか、複数の要素のインデクスをカンマ区切りで指定することもできます。
あるいは、次のように AttributeExposer を使ってリストの要素を現すこともできます。
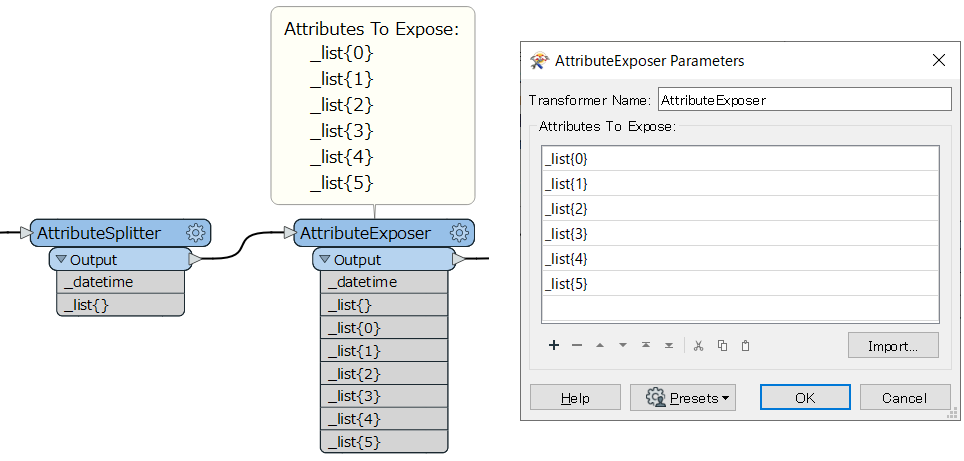
なお、リストの要素に限らず、ワークスペース実行時における個々のフィーチャーの属性の構成は、ワークスペースの作成時に FME Workbench のキャンバス上に現れている属性の構成とは必ずしも一致しないこと、つまり、現れている名前の属性を実行時のフィーチャーが必ず持っているとは限らない、逆に、インターフェース上に現れていない属性を持っている場合もあることに留意してください。実行時にフィーチャーが実際に持っている属性は、Logger によって内容をログに出力させるか、あるいは、Visual Preview か FME Data Inspector に出力して Feature Information ウィンドウで表示させることによって確認できます。
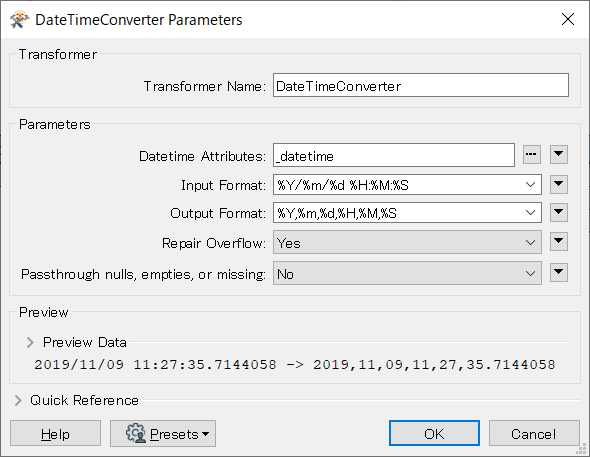
このケースのように分割前の文字列が特定の書式によって記述されている日付/時刻文字列である場合は、StringReplacer の代わりに DateTimeConverter によって同一の区切り文字による書式に変換することもできます。
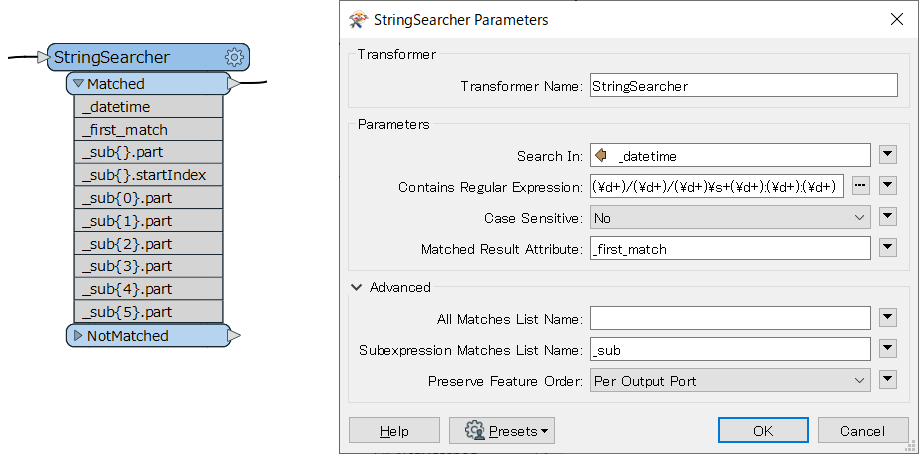
また、AtrributeSplitter を使わずに、StringSearcher だけで分割することも可能です。この場合は事前に書式を変換しておく必要はありません。
構造化リストについて
StringSearcher の Subexpression Matches List Name パラメーターにリスト名を指定すると、個々の部分式(正規表現中でカッコで括った部分)と一致する文字列と元の文字列におけるその部分の開始位置(元の文字列の先頭を0とする)がリスト属性に格納されます。一致した部分ごとに二つの値(文字列、開始位置)が取得できるわけですが、どちらの値であるかはリスト要素名に付加される “.part”、”.startIndex” というサフィクス(接尾辞)によって区別できます。
| _sub{} リストの要素 | _sub{i}.part の値 | _sub{i}.startIndex の値 |
|---|---|---|
| _sub{0}.part, _sub{0}.startIndex | 2019 | 0 |
| _sub{1}.part, _sub{1}.startIndex | 11 | 5 |
| _sub{2}.part, _sub{2}.startIndex | 08 | 8 |
| _sub{3}.part, _sub{3}.startIndex | 12 | 11 |
| _sub{4}.part, _sub{4}.startIndex | 34 | 14 |
| _sub{5}.part, _sub{5}.startIndex | 56 | 17 |
このようにひとつの要素に関連する複数の値を格納し、サフィクスによって区別できるようにしたリスト属性は実用的なワークスペースではよく現れ、AttributeSplitterなどが作成する通常のリスト属性(サフィクスがない)と区別する場合には、構造化リスト(Structured List または Complex List)と呼ぶこともあります。